how to get your substack consumption data
on a minor substack reader bug and scripting with marimo
As part of my efforts on lectara, I wanted to go through the posts I've read on Substack, exploring the data and reviewing my attention habits. To do that, I have to get my hands on the data. Unfortunately, I don't see a dedicated way to get my Substack consumer data; you can export a publication's data, but that isn't very helpful for my purposes.
Luckily for me:
- It is dead easy to see how the Substack web app populates the history page.
- There is prior art on making authenticated requests to Substack's API.
tldr
I threw together a marimo notebook to fetch my history data, roughly as if I was scrolling the history view; you can look at the code on GitHub. You can also open the notebook in your browser, but you won't be able to make the necessary requests to Substack's API.
a minor history view bug
My initial thought was to simply copy what the web app did. Watching the initial API request already
showed me that the history was populated by hitting /api/v1/reader/posts with query parameters
inboxType=seen and limit=20. seen was self-explanatory, and initial experimentation told me
that the backend validated limit, preventing me from requesting more than 20 posts at a time.
Obviously, I needed more than 20 posts, so I started scrolling and inspected the next request. The
next "page" is populated by sending nearly the same request, but with an additional after
parameter set to a timestamp. It wasn't obvious what this timestamp was supposed to be, since
after is a pretty generic parameter name; figures, since after is used to populate other types
of inbox tabs.
I loaded another "page" and did some basic transformations, which confirmed how the web app progressively rendered the history page:
- Of the last set of posts returned, identify the user's least-recently viewed post.
- Request the next "page" by setting
afterto the publish date of that least-recently viewed post.
initial_history = get("/api/v1/reader/posts",
params={ "inboxType": "seen", "limit": 20 })
lrv_post = min(initial_history["posts"],
key=lambda post: post["inboxItem"]["seen_at"])
next_history = get("/api/v1/reader/posts",
params={
"inboxType": "seen",
"limit": 20,
"after": lrv_post["post_date"]
})
Seemed a bit odd to use post_date instead of seen_at, but I figured I should mimic the web app
and went with it. Maybe there was some kind of benefit to using a publish date cursor that I
couldn't comprehend as an outsider.
I ran my script and got... 159 posts. Surely that wasn't right. At this point, I had only loaded 60 posts into my actual history, so I scrolled to the "bottom" and realized that my history page was suspiciously short as well.
I poked a little more and realized that when inboxType is seen, adding after transforms the
query into:
Starting from posts viewed before
after, please give me the next 20 posts in the history.
after was placing a ceiling on the possible values of post.inboxItem.seen_at; the frontend using
post_date was just a bug.
This bug wasn't obvious to me before, because the first 20 items are always correct. Plus, if you primarily read recent posts, the history will just be subtly wrong if it's wrong at all.
I was looking through some older posts though, and now this bug is super clear:
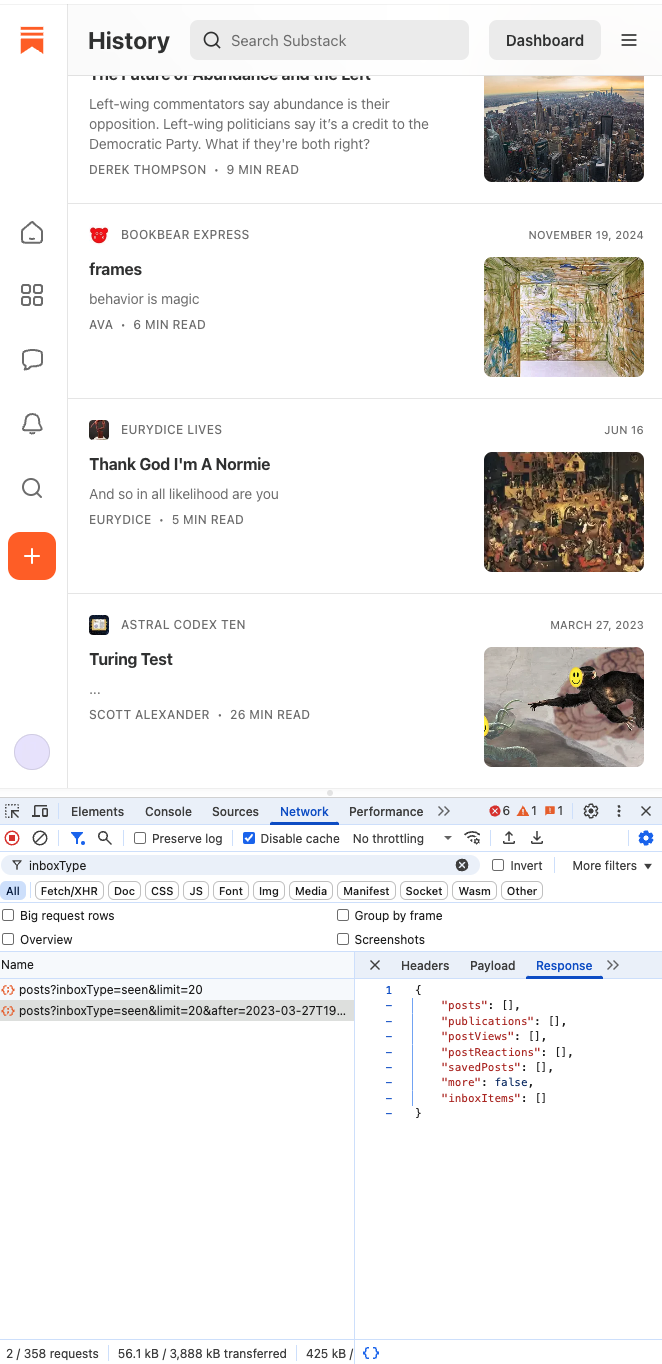
Since my least-recently viewed post was posted on March 27, 2023, the next history query uses that
date (and time) as the value of after. However, I didn't have a Substack account in 2023, so the
query returns nothing and it looks like I have only read 20 posts in my life.
I bet the fix is a very small code change on the web frontend, as the iOS app does this correctly :)
marimo is pretty cool
Since I was planning to do some request scripting and I was also familiar with pandas for data
wrangling, reaching for Python was an easy choice. I've used Jupyter in the past, but since this was
a low-stakes effort, I decided to try something new.
Interactive Python environments are fantastic for these kinds of exploratory tasks, but they have a well-known reproducibility problem. marimo is "an open-source reactive Python notebook" that tries to solve this. It has the UI niceties for tables and plotting that Jupyter environments have, but it also tracks data dependencies between cells, ensuring reproducibility. This also enhances usability, as modifying and running a given cell will also re-run dependent cells (or mark them as dirty if auto-rerun is disabled).
This is much closer to typical programming than Jupyter Notebooks are, in my opinion, so I had a much better time using marimo. It's harder to get into an invalid state, and it also means cell placement does not matter. Notebooks don't have to be written to be run from top to bottom, separating presentation from functionality.
I was also impressed with how many batteries are included. The editor has been pleasant so far, and
if you try to import a module without its associated package, marimo will prompt the user with a
"click to add with uv" button. Neat!
There's even a dedicated UI library. You can use marimo to prototype an interactive app exposing your notebook's functionality without fiddling with all the options that a full frontend framework provides; the provided UI elements are functional and they otherwise get out of the way. Very pragmatic.
Writing a Substack history export frontend doesn't interest me that much, but I did it because marimo makes it so incredibly easy to go from a personal script to a functional-enough app. Without marimo, this tiny bit of work would just live as a static notebook in the lectara GitHub repository, but now anyone can point marimo.app to this notebook's GitHub repository and mess with the notebook.
You sensibly can't use it to fetch your Substack data because of CORS restrictions, but it's very cool that this WASM-powered notebook frontend exists at all. If you get your hands on your data, you can easily modify the notebook to run the rest of the code, turning responses into a dataframe without ever leaving the browser.
closing thoughts
This was a reasonably fun diversion, and I'm feeling good about exploring my Substack data further.
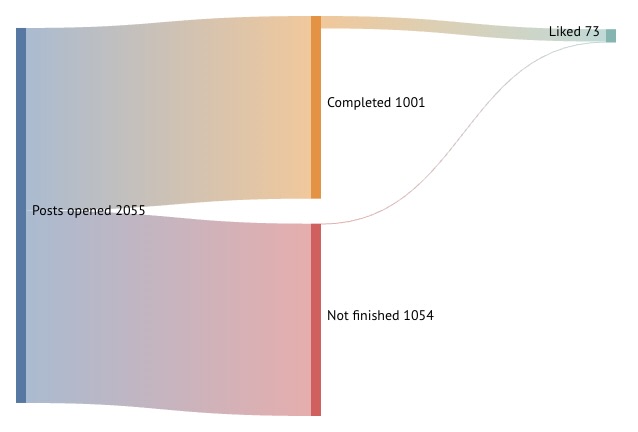
Before starting this, I didn't think very hard about it and thought that the history would just be a list of post IDs or something; I'm pleasantly surprised that the primary response includes basically all the data I would have wanted, including:
- post metadata like ID, canonical URL, word count, title, and bylines
- my interaction data like restacks and likes (the latter is also referred to as just a "reaction")
- my progress data: how far in to the post did I stop? what is the furthest I have gone?
I hope this is helpful to someone :)
<3
if you'd like, check out my website, seridescent.com